Essential Python Interview Questions & Answers For Data Science

Python has become the most popular programming language among data scientists worldwide. Best known for its reliability, extensive libraries, and active community, Python empowers data enthusiasts to analyze data, build models, and deploy scalable machine learning applications with ease. Whether you are a student preparing for your first data science role or a working professional aiming to switch careers, mastering Python interview questions is essential to take the first step towards your dream job.
At Bhrighu Academy, our hands-on project-based curriculum prepares learners with practical skills and interview readiness. This comprehensive guide will help you with a collection of Python interview questions and answers to help you stay ahead of the competition.
What is Python, and List Some of its Key Features?
Python is a high-level, interpreted programming language that supports multiple programming paradigms, including procedural, object-oriented, and functional programming. Due to its simplicity and robust libraries, Python is widely used in Data Science, machine learning, web development, automation, and scripting
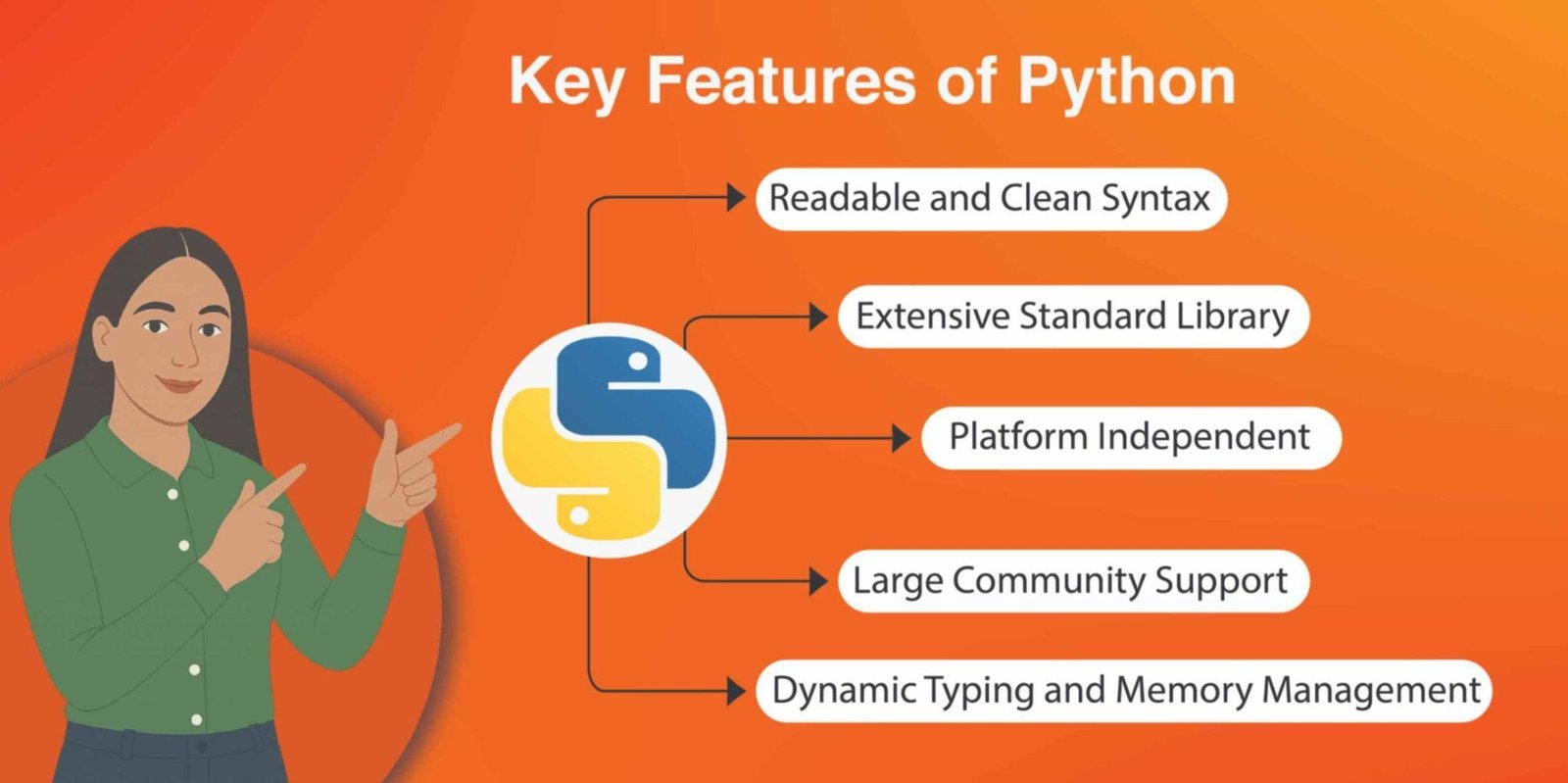
These are some of the main characteristics of Python that contribute to its resilience.
Readable and Clean Syntax:
Designed to be readable and concise, promoting rapid development.
Extensive Standard Library:
This library offers modules and packages for tasks like file I/O, regular expressions, databases, and data manipulation.
Dynamic Typing and Memory Management:
Reduces boilerplate code.
Platform Independent:
Code can run on different operating systems with minimal modification.
Large Community Support:
Rich ecosystem of libraries and frameworks, especially for data science (NumPy, Pandas, Scikit-learn, etc.).
18 Python Interview Questions Every Data Scientist Should Know
Here are 18 Python interview questions and answers that cover essential concepts, advanced techniques, and real-world applications of Python in Data Science.
1. What is the Global Interpreter Lock (GIL) in Python, and Why is it Important?
The standard Python interpreter, CPython, has a mutex called the Global Interpreter Lock (GIL) ensuring that only one thread runs Python bytecode at a time. This simplifies memory management but limits true multithreading capabilities.
Importance:Prevents race conditions in memory operations.
Limits CPU-bound parallelism in multithreaded applications.
For I/O-bound tasks, Python’s multithreading can still be effective.
2. Can You Explain Common Searching and Graph Traversal Algorithms in Python?
Yes. Common algorithms include:Binary Search: for sorted data. Implemented using loops or recursion.
Breadth-First Search (BFS):Investigates all of its neighbors, ideal for issues involving the shortest path.
Depth-First Search (DFS):Explores as deep as possible before backtracking. It is helpful in detecting cycles
Libraries Used: NetworkX (for graphs), collections.deque (for BFS queues).
3. What is the Python “with” Statement Designed for?
The with statement makes it easier to handle resources like database connections and file streams.
Example:
with open("data.txt", "r") as file:
content = file.read()
This ensures the file is automatically closed, even if an exception occurs.
4. How Does Python Handle Memory Management, and What Role Does Garbage Collection Play?
Python employs a cyclic garbage collector and automated memory management with reference counting.
Reference Counting:Counts how many times each object has been mentioned.
Garbage Collection:Detects and clears cycles—objects referencing each other but no longer accessible.
The gc module allows manual interaction with the garbage collector if needed.
5. What is the Difference Between Shallow Copy and Deep Copy in Python, and When Would You Use Each?
Shallow Copy:Copies the outer object but not nested objects. Uses copy.copy().
Deep Copy:Copies everything recursively. Uses copy.deepcopy().
Use shallow copy when the inner elements are immutable or shared intentionally. When a comprehensive, separate copy of every nested item is needed, use deep copy.
6. How Can You Use Python’s Collections Module to Simplify Common Tasks?
The collections module provides alternatives to built-in types:
Counter: for counting hashable items.
defaultdict: auto-initialises missing keys.
OrderedDict: remembers insertion order (Python 3.7+ has built-in order).
deque: fast appends/pops from both ends.
from collections import Counter
Counter(['apple', 'banana', 'apple'])
7. What is Monkey Patching in Python?
Monkey patching refers to modifying or extending code at runtime, often by replacing methods or classes.
Use case: Adding logging or testing behavior without modifying the original codebase.
Caution: It can lead to maintainability issues if overused.
8. Why Use else in the try/except construct in Python?
The else block runs only if the try block succeeds without exceptions.
Purpose: It separates code that should run only on success, improving readability.
Example:
try:
result = risky_function()
except ValueError:
handle_error()
else:
use_result(result)
9. What are Context Managers in Python, and How Are They Implemented?
Context managers can be used with statements to automatically handle setup and takedown operations.
Implemented via:__enter__() – code to run before block.
__exit__() – cleanup code.
class CustomContext:
def __enter__(self):
# setup
def __exit__(self, exc_type, exc_value, traceback):
# cleanup
10. What Library Would you Prefer for Plotting, Seaborn or Matplotlib?
Seaborn is built on top of Matplotlib, offering a high-level API and better aesthetics for statistical plots.
Use Seaborn for:Quick exploratory data visualisation.
Built-in themes and color palettes.
Complex visualisations (heatmaps, pair plots).
You need fine-grained control over the visual elements.
11. Which Python Libraries Have You Used for Visualization?
Matplotlib – Foundation of plotting in Python.
Seaborn – Statistical data visualisation.
Plotly – Interactive charts and dashboards.
Altair – Declarative statistical visualisation.
Bokeh – Browser-based visualisation for large datasets.
12. How Would You Normalise or Standardise a Dataset in Python?
Normalization: Scales features to [0, 1]. Use MinMaxScaler from sklearn.preprocessing.
Standardization: Scales features to have mean = 0 and std = 1. Use StandardScaler.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
13. How Would you Find Duplicate Values in a Dataset for a Variable in Python?
Using Pandas:duplicates = df[df.duplicated('column_name')]
This returns rows with duplicate values in the specified column.
To remove duplicates:df.drop_duplicates('column_name', inplace=True)
14. How Do You Handle Missing Data in a Dataset Using Python?
Common techniques include:Removal: df.dropna()
Imputation: df.fillna(value) or using SimpleImputer from scikit-learn.
Advanced: Filling in missing values with KNN or predictive imputation.
The volume and pattern of missingness determine the strategy.
15. How Would You Clean and Preprocess a Large Dataset for Machine Learning in Python?
Steps include:1. Missing Value Handling – dropna, fillna, imputation.
2. Outlier Detection – IQR method or z-scores.
3. Encoding Categorical Data – OneHotEncoder, LabelEncoder.
4. Feature Scaling – Normalisation or standardisation.
5. Text Preprocessing – Tokenisation, stemming, lemmatisation.
6. Handling Imbalanced Data – Using SMOTE or resampling.
Use pandas, numpy, sklearn, and nltk as needed.
16. Compute the Inverse of a Matrix in NumPy?
Use numpy.linalg.inv():
import numpy as np
A = np.array([[1, 2], [3, 4]])
inv_A = np.linalg.inv(A)
Ensure the matrix is non-singular (det ≠ 0) before inverting.
18. Explain How You Would Handle Skewed Data During Preprocessing in Python.
Techniques include:Log Transformation: np.log(x + 1) for right-skewed data.
Box-Cox or Yeo-Johnson Transformation: From scipy.stats or sklearn.preprocessing.
Binning: Converting numeric data into categorical.
Resampling or Balancing Classes: For classification problems with skewed targets.
The choice depends on the severity and context of skewness.
Wrapping up
Python remains a cornerstone of modern data science, and mastering its concepts is essential for cracking Python basic interview questions. Understanding the fundamental principles and applying best practices significantly enhances your chances of landing high-impact roles in data-driven industries.
At Bhrighu Academy, we ensure that learners understand these concepts and apply them through hands-on, industry-based projects and Python interview preparation. Our curriculum is designed to equip students with the tools, frameworks, and confidence to succeed in data science roles globally.
Enrol now to begin your journey towards career excellence with NASSCOM-certified programs, expert mentorship, and dedicated placement support.
Frequently Asked Questions
How should I prepare for a Python interview?
To prepare for a Python interview, start by mastering the fundamentals of Python, including data types, control structures, functions, and OOP concepts. Practice frequently asked questions related to data science, such as list comprehensions, NumPy operations, Pandas transformations, and machine learning workflows. Work on hands-on projects and review your code for clarity and efficiency. Understanding libraries like Scikit-learn, Seaborn, and Matplotlib will help demonstrate your practical skills during technical interviews.
How to crack Python technical interview questions?
Cracking Python interview questions requires a blend of theoretical knowledge and practical application. Focus on Python’s syntax, key libraries, data manipulation techniques, and algorithms. Solve coding problems regularly on platforms like LeetCode or HackerRank to build problem-solving speed. Be ready to explain your logic clearly and demonstrate how you approach debugging or optimising code. Also, revise real-world use cases from past projects to confidently answer scenario-based or applied questions.
What are Python's key features that make it popular in Data Science?
Python's popularity in data science stems from its simplicity, readability, and robust ecosystem of libraries like Pandas, NumPy, Matplotlib, Seaborn, and Scikit-learn. It supports rapid prototyping, interactive computing, and seamless integration with machine learning frameworks. Python’s interpreted and dynamically typed nature allows for faster development. Additionally, its large community, extensive documentation, and wide use across academia and industry make it a top choice for data-driven tasks and research.
How is Python used in data preprocessing?
Python is critical in data preprocessing and is essential for building accurate machine-learning models. Libraries like Pandas help handle missing values, encode categorical data, and remove duplicates. NumPy is used for numerical computations and array transformations. Scikit-learn offers preprocessing modules for scaling, normalization, and imputation. With these tools, Python allows data scientists to clean, transform, and prepare large datasets efficiently, ensuring they’re ready for training or analysis.



